Management Console
Overview
The Management Console is a user-friendly front-end interface built on top of the any inference engine (Doubleword, vLLM, SGLang). It provides a single pane of glass for managing, deploying, and monitoring AI models across your entire deployment infrastructure. This document outlines the key features and functionalities of the Management Console, organized by its main panels and sections. The management console sits in front of all of your Doubleword Clusters whether that's multiple clusters running in one environment, or clusters running in a multi-cloud environment or split across cloud infrastructures and on-premise.
Deployment Overview
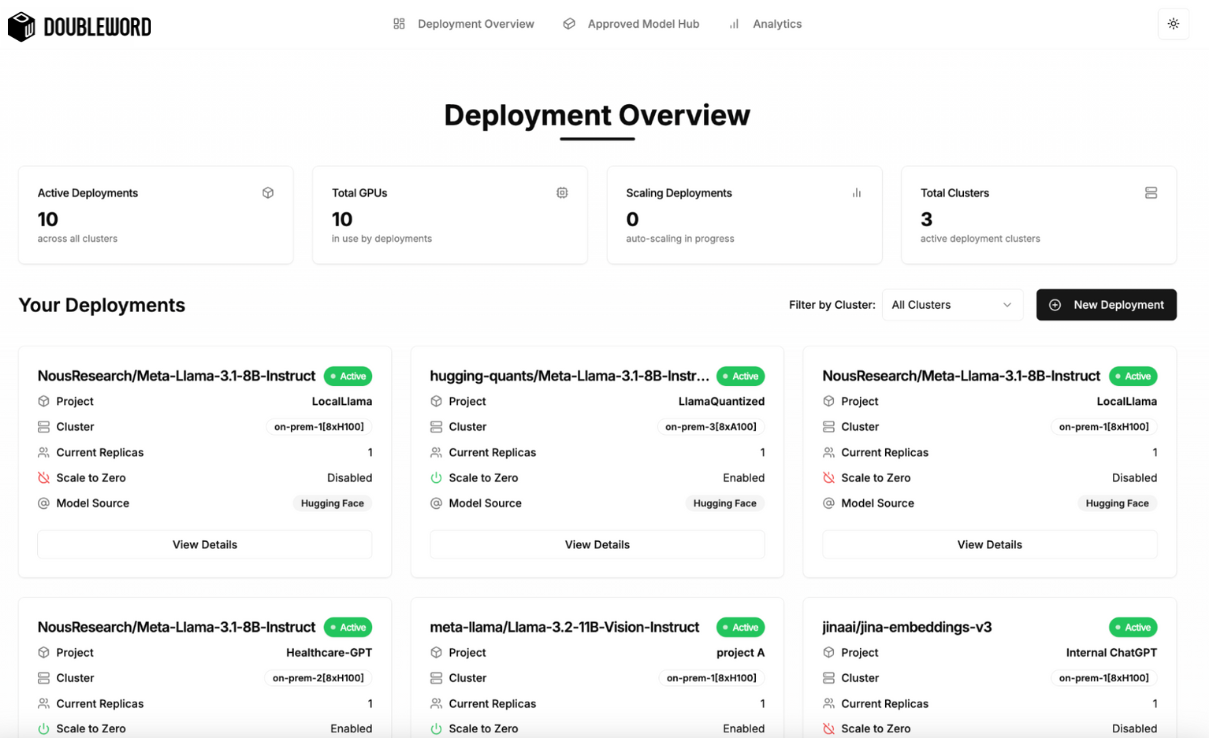
The Deployment Overview page offers a high-level summary of all active deployments, providing visibility into the deployment landscape. This single view of all deployments simplifies management and oversight, making it easier to track progress and performance. If you are interested in learning more about a specific model deployment you can simply click into the “View Details Section".
Deployment Details

The Deployment Details Page offers comprehensive insights into specific deployments, showcasing configuration settings and high-level performance metrics. Administrators can efficiently manage deployments by scaling them up or down, or stopping them entirely as needed. Additionally, the Playground tab allows for model testing, ensuring that expected outputs are achieved before providing the API to downstream users for application development.
Metrics
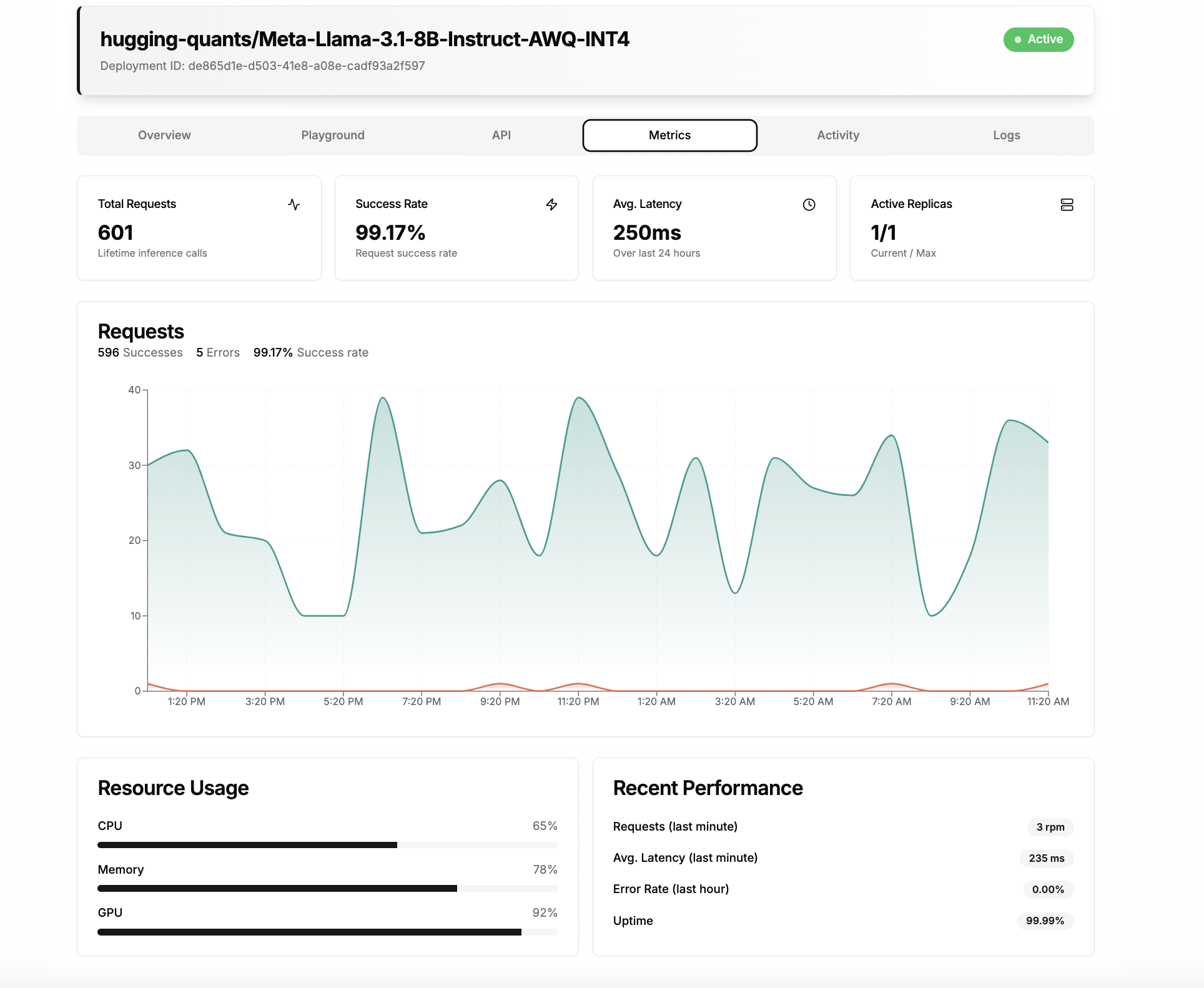
This page also features model-level metrics, such as the total number of requests and average latency, enabling administrators to gauge model traffic effectively. The metrics on this page can be customized to include any of the 70+ metrics we capture from our Prometheus server. The activity tab maintains a detailed record of deployment history, capturing information on who deployed the model and when, as well as any scaling actions taken.
Approved Model Hub

The Model Hub serves as a centralized repository for available models, facilitating easy access and deployment. This repository can be simply integrated to existing model repositories such as Huggingface, Weights & Biases or other upstream systems that may exist in the organizations. Users can search and filter models by source, task, industry, and language, enhancing discoverability and selection efficiency. When a downstream user requires a new model for their application, administrators can utilize the one-click deployment button to quickly select the necessary details, enabling a model to be up and running in just minutes.
Model Deployment
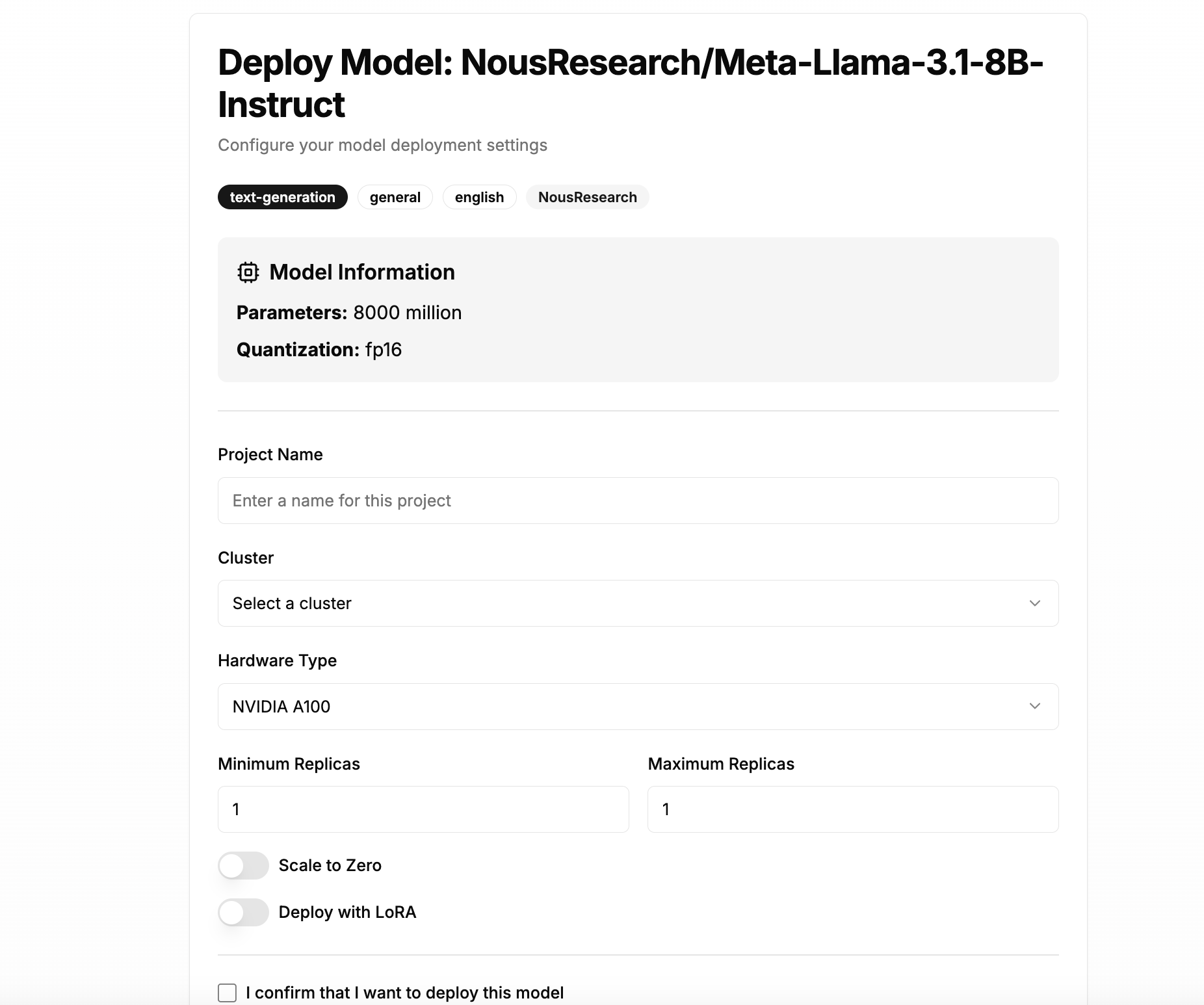
The Model Deployment Panel facilitates the configuration of model deployment settings, allowing users to tailor their deployments to meet specific project needs. Key elements include:
Model Information: Displays essential details such as parameters and quantization type, ensuring users have the necessary context for their deployment.
Project Name and Cluster Selection: Users can easily assign a project name and select the appropriate cluster for deployment, streamlining the setup process.
Hardware Type: The option to choose hardware with built in control to ensure you are deploying a model on a machine with enough RAM. You can deploy a model on any GPU (e.g. Nvidia, AMD, Intel etc.) or CPU.
Replica Management: Administrators can define minimum and maximum replicas, enabling efficient resource allocation and scalability.
Advanced Options: Features like "Scale to Zero" and "Deploy with LoRA" provide flexibility in deployment strategies.
Once your model is deployed you will be redirected to the Deployment Overview to see this new deployment alongside other models.
Cluster Analytics
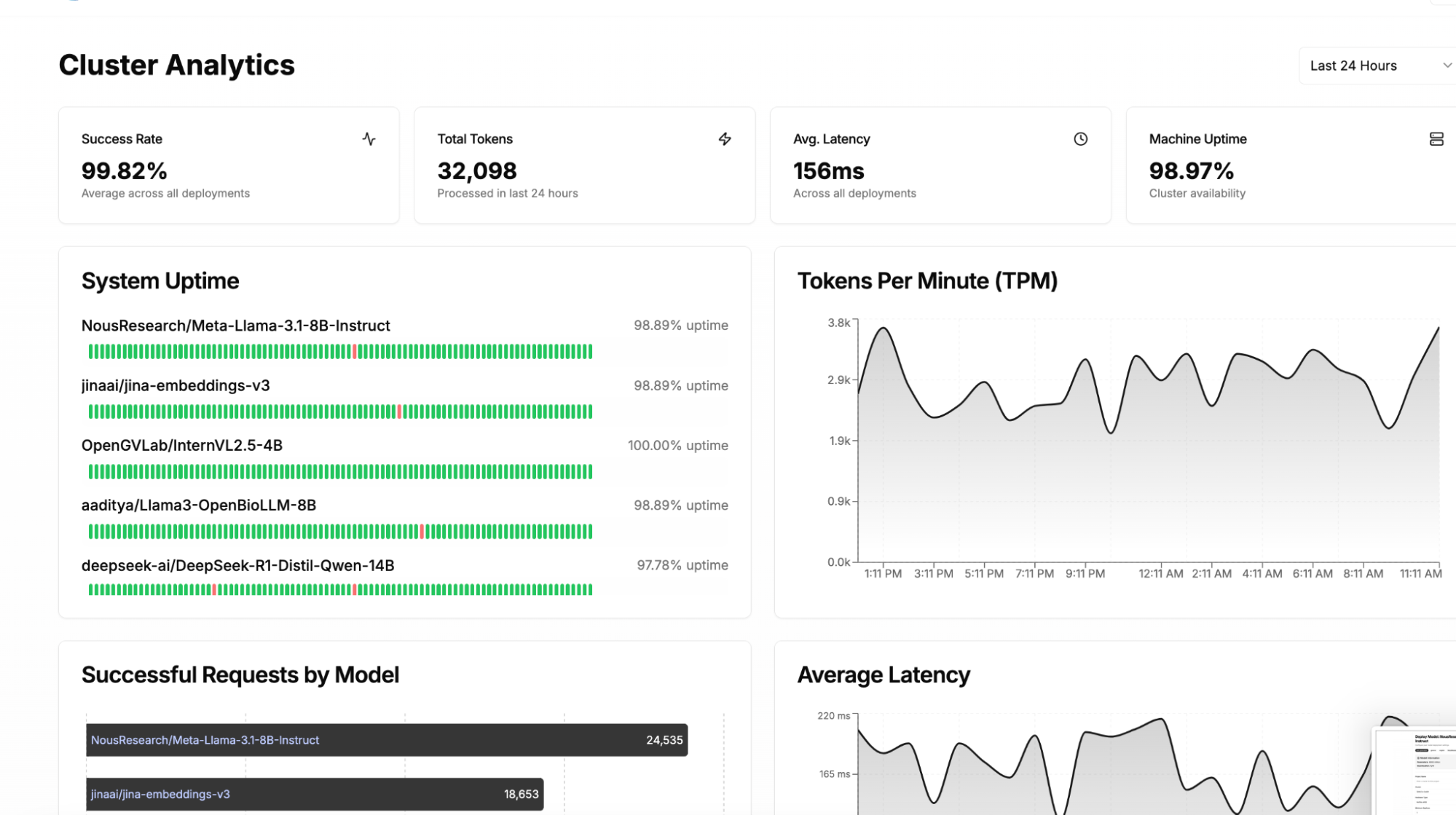
The Cluster Analytics panel provides summarized insights into the performance and health of all deployed models. This page provides an administrator with understanding of usage patterns allowing better allocation of resources, leading to cost savings and improved operational efficiency. Similar to the model metrics page, this page can be customized to metrics that matter to your business.